.png%3Falt%3Dmedia%26token%3D5bfaabb1-e87f-402c-9e3d-19820ace769d&w=3840&q=75)
「自己教師あり学習」という言葉を聞いたことはあるけれど、具体的にどういう技術なのかよくわからない——そんな方も多いのではないでしょうか。
自己教師あり学習(Self-Supervised Learning)とは、AIがデータの一部を隠し、その隠された部分を予測することで自ら学習する手法です。ChatGPTやBERTなど、最先端の生成AIの基盤技術として広く採用されています。
この記事では、自己教師あり学習の基本的な意味から仕組み、ビジネスでの活用例までをわかりやすく解説します。
目次
1. はじめに
従来のAI学習では、大量の「正解ラベル付きデータ」を人間が用意する必要がありました。しかし、ラベル付けには膨大なコストと時間がかかります。
自己教師あり学習は、この課題を解決する技術です。AIが自分自身で「疑似的な正解」を作り出して学習するため、人間によるラベル付けが不要になります。ChatGPTが膨大な知識を持ち、さまざまな質問に柔軟に答えられるのは、この自己教師あり学習によるものです。
2. 自己教師あり学習とは
自己教師あり学習とは、AIがデータの一部を隠して、その隠された部分を予測するタスクを通じて自ら学習する手法です。
たとえば、文章の一部を隠して「この空欄に入る言葉は何か?」を予測させます。「私は__を飲むのが好きです」という文章があれば、AIは多くの文章を読む中で「コーヒー」「お茶」「水」などが入りやすいことを学びます。
このように、データの一部を隠してそれを推測することで、AIは「文脈を理解する力」を自然に身につけていきます。
教師あり学習・教師なし学習との違い
学習の種類 | 教師の有無 | 特徴 |
|---|---|---|
教師あり学習 | 人間が正解ラベルを付与 | 正解をもとに予測・分類を学習 |
教師なし学習 | ラベルなし | データ構造を自動的に発見 |
自己教師あり学習 | AIが疑似的な正解を生成 | ラベルなしデータから高精度に学習 |
自己教師あり学習は「教師あり学習」と「教師なし学習」の中間に位置する手法です。人間がラベルを付ける手間を省きながら、教師あり学習に近い精度を目指せるのが大きな特徴です。
3. 身近で使われている自己教師あり学習の例
自己教師あり学習は、すでにさまざまなサービスで活用されています。
サービス・技術 | 自己教師あり学習の役割 |
|---|---|
ChatGPT | 文章の次の単語を予測するタスクで言語を理解 |
BERT(Google) | 文章の一部を隠して予測するタスクで文脈を理解 |
画像の一部をマスクして復元するタスクで視覚的特徴を学習 | |
音声認識 | 音声の一部を消して再構成し、発話パターンを理解 |
動画分析AI | 次のフレームを予測して動きのパターンを学習 |
特にChatGPTは、膨大なテキストデータを使った自己教師あり学習(事前学習)によって言語の構造や知識を獲得し、その後のファインチューニングで会話能力を磨いています。
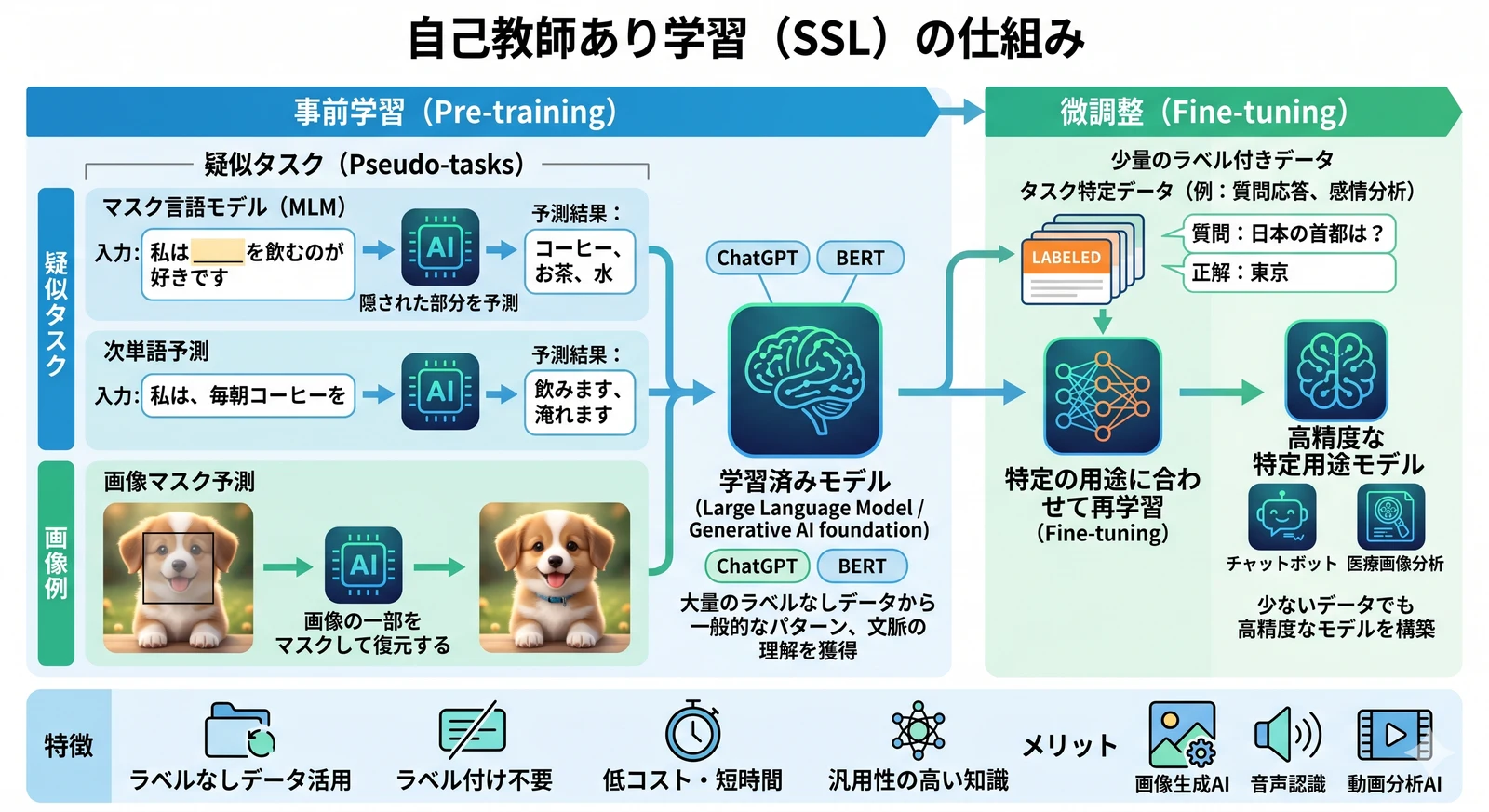
4. 自己教師あり学習の仕組み
自己教師あり学習は、主に「事前学習(Pre-training)」と「微調整(Fine-tuning)」の2つの工程で構成されます。
事前学習(Pre-training)
大量のデータを使ってAIに一般的なパターンを学ばせる段階です。このとき正解ラベルは不要で、AIが自ら「疑似的なタスク」を設定して学習します。
代表的な疑似タスクには以下のようなものがあります。
マスク言語モデル:文章の一部を隠して予測させる(BERTで使用)
次単語予測:文章の続きを予測させる(GPTシリーズで使用)
画像マスク予測:画像の一部を隠して復元させる
微調整(Fine-tuning)
事前学習で得た知識をもとに、質問応答や感情分析など特定の用途に合わせて再学習する段階です。事前学習で獲得した汎用的な知識があるため、少量のデータでも高精度なモデルを構築できます。
5. ビジネスでの活用
自己教師あり学習はさまざまなビジネス分野で活用されています。
自然言語処理:ChatGPTやBERTなどの基盤技術。チャットボット、文書要約、感情分析に活用
画像認識:ラベルなし画像データから特徴を学習し、少ないラベルで高精度な分類を実現
音声処理:音声データから発話パターンを学習し、音声認識の精度を向上
動画分析:動画の動きパターンを学習し、監視カメラや行動分析に活用
医療:ラベル付けが困難な医療画像データから特徴を事前学習
検索エンジン:テキストの意味理解を向上させ、検索精度を改善
アプリ開発の分野でも、自己教師あり学習は以下のような形で導入されています。
少ないラベルデータで高精度な分類機能を実装
大規模言語モデルを業務特化型に微調整したAIアシスタント
画像・テキストの自動分類や要約機能
ユーザーの行動パターンを学習するパーソナライズ機能
6. 関連用語
自己教師あり学習に関連する用語をまとめました。それぞれの用語を理解することで、AI技術への理解がさらに深まります。
教師あり学習:正解ラベル付きデータを使ってモデルを学習させる手法
教師なし学習:正解ラベルなしでデータの構造やパターンを発見する手法
事前学習(Pre-training):大規模データでモデルの基礎知識を学習させるプロセス
ファインチューニング:学習済みモデルを特定用途に合わせて追加学習する手法
LLM(大規模言語モデル):大量のテキストデータで学習した言語処理AI
7. まとめ
自己教師あり学習とは、AIがデータの一部を隠して予測するタスクを通じて自ら学習する手法です。
人間によるラベル付けが不要なため、膨大なデータを効率的に学習でき、ChatGPTやBERTなどの最先端AIの基盤技術として広く活用されています。教師あり学習と教師なし学習の中間に位置し、両者の長所を兼ね備えた手法です。
今後、自己教師あり学習のさらなる進化により、AIはより少ないデータで多くのタスクをこなせるようになり、「自ら学び、適応するAI」への発展が期待されています。
8. AI開発・アプリ開発のご相談
自己教師あり学習は、ラベル付けのコストを削減しながら高精度なAIを実現するための重要な技術です。ChatGPTのような大規模言語モデルの基盤としても活用されています。
micomia株式会社では、自己教師あり学習をはじめとするAI技術を活用したアプリ開発・システム開発を行っています。AI導入やアプリ開発をご検討の方は、お気軽にご相談ください。

.webp%3Falt%3Dmedia%26token%3D554beac3-1f0a-4dae-99c0-76320019500f&w=3840&q=75)







.webp%3Falt%3Dmedia%26token%3D087cf100-0101-43ba-a354-dab3bbec04d2&w=3840&q=75)
.webp%3Falt%3Dmedia%26token%3D7c77ae76-450c-48b3-be29-0e949e7116dc&w=3840&q=75)
.webp%3Falt%3Dmedia%26token%3Dd8f3f5bc-41c2-4a1e-ace1-62e9ae72d08b&w=3840&q=75)
.webp%3Falt%3Dmedia%26token%3D679eb351-4808-4d43-8b9d-92f6a88584ef&w=3840&q=75)
.webp%3Falt%3Dmedia%26token%3D5c25485e-7be1-4f95-ad65-2e4c0c2d0ddb&w=3840&q=75)

.webp%3Falt%3Dmedia%26token%3D1875ff54-2eaa-4913-8d8c-9a4855927112&w=3840&q=75)
.webp%3Falt%3Dmedia%26token%3Da7c14698-1b08-4fea-89c6-f77a9121f4c5&w=3840&q=75)
.webp%3Falt%3Dmedia%26token%3D900f385d-12a2-449b-8d1e-83a57cef0088&w=3840&q=75)
.webp%3Falt%3Dmedia%26token%3D0e802fb0-2dda-44a7-bf80-5d39019635ba&w=3840&q=75)
.webp%3Falt%3Dmedia%26token%3D899eeefd-f4c9-44a6-9ec2-3ced0b223ffd&w=3840&q=75)